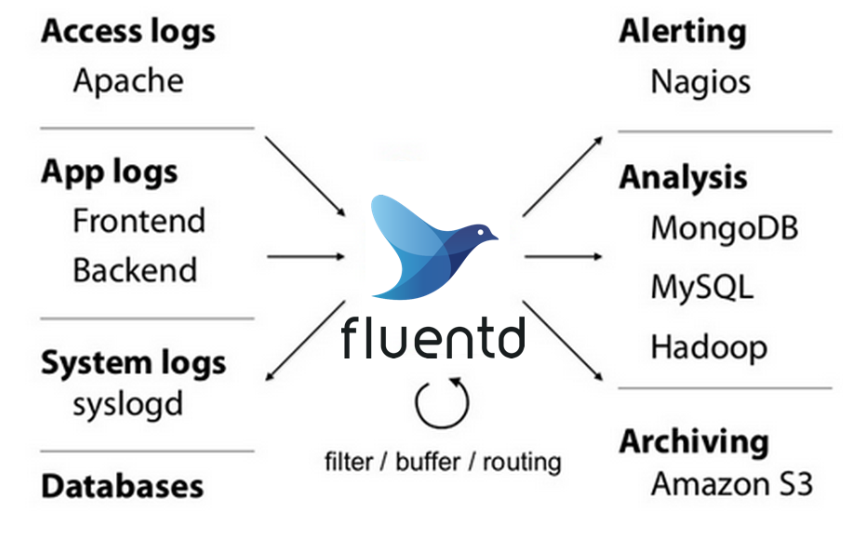
Companies that want to collect gobs of observability data but process the data in multiple places while keeping it free from analytic tool vendor’s proprietary formats may be interested in Fluentd, an open source data collector that decouples data sources from the proprietary backends used in services like Splunk, Elastic, and Datadog.
Fluentd (pronounced “fluent-dee”) was conceived in 2011 by Treasure Data co-founder Sadayuki Furuhashi as way to address the challenge of big data log collection. While the flow of observability data (such as logs, metrics, and traces) was not as high back then as it is now, the complexity problem was a concern, particularly when trying to merge log data that not only originated from different systems (Windows vs. Linux vs. MacOS) but also is landed on different systems for storage and analysis (Hadoop, MongoDB, S3, etc.).
With Fluentd, Furuhashi created a unifying log layer that would standardize how the log data is captured and stored. Specifically, Fluentd converts all log data into JSON, which was just emerging as a data standard in the early 2010s but has become nearly ubiquitous since.
Fluentd was written primarily in C, but with a Ruby wrapper that makes it easier to develop plug-ins. That pluggable architecture has been instrumental in helping the Fluentd project to grow, with 500 plug-ins recommended by the Fluentd organization, and another 500 or so unofficial plug-ins available too.
With observability data now stored a vendor-neutral format–and with hundreds of plug-ins enabling that data to move freely among different systems–Fluentd users gain more power to intercept, process, delete, or analyze data on the platform of their choice, rather than being locked into a single proprietary format.
In 2011, Furuhashi open sourced Fluentd, making it available in the permissive Apache 2.0 license, and it began to gain traction as a more versatile version of Logstash that works beyond the popular ELK (Elastic, Logstash, Kibana) stack.
(Image courtesy: Fluentd)
By 2016, the Fluentd project was accepted to the Cloud Native Computing Foundation, where, together with Prometheus, it has become part of the standard observability kit for tracking Kubernetes container environments. It became a Graduated Project at the CNCF in 2019.
In 2015, Treasure Data released Fluent Bit, which is a smaller, faster version of Fluentd. Created in straight C, Fluent Bit has fewer dependencies than Fluentd and consumes less memory, making it an ideal data collector for embedded Linux environments. Meanwhile, Treasure Data was acquired by Arm in 2018 for a reported $600 million, and continues to develop its customer data platform as well as sponsoring and supporting Fluentd and Fluent Bit.
Over the years, Fluentd and Fluent Bit have been adopted by large companies with massive data movement challenges, including large banks and healthcare companies, as well as the cloud giants, which embed Fluentd and Fluent Bit into their Kubernetes distributions.
But in the past year, adoption of the two open source projects has skyrocketed, going from 1 billion downloads in March 2022 to about 4 billion downloads today, according to Anurag Gupta, who co-founded Calyptia, a Fluentd and Fluent Bit-based services company, with Eduardo Silva in 2020.
“It’s spiking tremendously,” Gupta says. “We’re just seeing a huge uptick, especially as users are getting more and more containers. And we’re seeing thousands and thousands of organizations join the community.”
The Fluentd and Fluent Bit Slack channel has about 8,500 members, according to Gupta. He says the cadence of comments and discussions is right up there with the volume he witnessed at Elastic, where he previously was a principal product manager.
What’s driving demand, Gupta says, is the desire among companies to regain control over their observability data environments, which they feel has gotten out of hand, particularly in the cloud.

(BEST-BACKGROUNDS/Shutterstock)
“I think in 2023, we’re going to see users question their bills on these observability solutions. They’re going to say, hey, look, we’re paying $1 million per year for this vendor and it’s gone up 20% to 30% year over year. Are we gaining more value from it? And if we aren’t, why are we paying more?” Gupta tells Datanami. “And I think that question’s going to come up, especially in this kind in this environment we’re in right now where people are looking at cost, investigating things really keenly.”
Gupta doesn’t question that tool vendors like Elastic, Splunk, Datadog, and New Relic, as well as the cloud giants AWS, Microsoft Azure, and Google Cloud–are providing some value to their customers. But he does question the need for a business model that’s based on charging by data volumes, particularly when much of the data being charged for is of questionable value.
“Vendors today are associated with volume, not value, and that creates a bad incentive to say, hey, we want to collect everything and send everything so you get a holistic view,” he says. “But in reality, we know there’s a lot of junk out there. If I’m sending debug logs, the fact is, it’s probably not useful for my security context. If someone accidentally turned that on, I’m getting charged the same $2 per GB.”
By interrupting that observability data pipeline, Fluentd and Fluent Bit can give users more control over where that data goes. Customers can use Fluentd and Fluent Bit to create processing rules that route particular pieces of observability to a particular cloud analytic vendor, to a Kafka topic, or even just deletes it. That allows customers to minimize their big data management requirements and cut cloud costs.
“We’re kind of saying, well, big data is big cost,” Gupta says. “The reality is there’s a lot of junk in big data and we are smart enough, the industry is smart enough, to know what’s junk and what’s not. But unfortunately, that junk is priced the same way that value is. And it’s hard to decouple it. Vendors kind of have to work against themselves in some way.”
Vendor are starting to respond to these forces by offering things like cheaper long-term storage and the ability to drop the data before it hits the system, Gupta says. They’re also adopting open formats, such as OpenTelemetry, which has gained momentum among vendors over the past couple of years as a standard for logs, traces, and metrics.![]()
However, not all OpenTelemetry implementations are equal, according to Gupta, who says some vendors who have adopted the standard have not done so in an open manner.
“I’m so amazed to see this, being in the industry for 10 years,” Gupta says of the push to adopt OpenTelemetry. “The downside is they created distributions of OpenTelemetry that only support their particular back-end, so a little bit of a revert back to that lock-in.”
Those types of moves only help to fuel adoption of Fluentd and Fluent Bit, which can help to eliminate that lock-in by vendors who have “adopted” OpenTelemetry, according to Gupta.
“A user wants to have a vendor-neutral agent that they control based on open source and be able to route that data wherever they may so choose,” he says. “It’s being drawn out by these customers, especially as they try to reduce the amount of data they sent to some of these costlier backends that have high billing.”
Demand for the open source projects is also helping to fuel demand for Calyptia’s two paid cloud services, called Calyptia Core and Calyptia Fluent Bit. The services use the “open core” of the Fluentd and Fluent Bit open source projects, and then add the sort of capabilities and features demanded by enterprises, such as a GUI management console, a no-code builder, as well as monitoring and management services.
“What we do from Calyptia side is we empower that engineer to be able to create four to five of these things without having to memorize all that configuration,” Gupta says. “We operate it for them, making it really highly available at things like auto healing, automatic storage, retry–all the best practices.”
The company launched its enterprise offering in October, and has moved into production with a handful of users, which are generating more than 100 TB of data per day in the Calyptia environment. In the meantime, the company also continues to be active in developing the open source Fluentd and Fluent Bit projects, which continue to see accelerating adoption.
Related Items:
Observability Primed for a Breakout 2023: Prediction
OpenTelemetry Gains Momentum as Observability Standard
AWS Charts a Multi-Pronged Path to IT Observability
cloud costs, decouple, Fluent Bit, Fluentd, logs, metrics, observability, observability data, OpenTelemetry, proprietary formats, traces