Herbal Language Processing is known as NLP. This can be a subset of man-made intelligence that allows machines to realize and analyze human languages. Textual content or audio can be utilized to constitute human languages.
The herbal language processing (NLP) pipeline refers back to the collection of processes interested by inspecting and working out human language. The next is a regular NLP pipeline:
The elemental processes for all of the above duties are the similar. Right here we now have mentioned one of the vital maximum commonplace approaches that are used all over the processing of textual content records.
NLP Pipeline
Compared to normal mechanical device finding out pipelines, In NLP we want to carry out some additional processing steps. The area could be very easy that machines donât perceive the textual content. Right here our largest downside is Tips on how to make the textual content comprehensible for machines. Probably the most maximum commonplace issues we are facing whilst appearing NLP duties are discussed under.
- Information Acquisition
- Textual content Cleansing
- Textual content Preprocessing
- Function Engineering
- Type Construction
- Analysis
- Deployment

NLP Pipeline
1. Information Acquisition :
As we all know, For construction the mechanical device finding out style we’d like records associated with our downside statements, On occasion we now have our records and On occasion we need to to find it. Textual content records is to be had on internet sites, in emails, in social media, in type of pdf, and plenty of extra. However the problem is. Is it in a machine-readable structure? if within the machine-readable structure then will or not it’s related to our downside? So, Very first thing we want to perceive our downside or activity then we must seek for records. Right here we can see one of the vital tactics of accumulating records if it isn’t to be had in our native mechanical device or database.
- Public Dataset: Â We will be able to seek for publicly to be had records as consistent with our downside commentary.Â
- Internet Scrapping: Internet Scrapping is a method to scrap records from a web page. For this, we will be able to use Stunning Soup to scrape the textual content records from the internet web page.Â
- Symbol to Textual content:  We will be able to additionally scrap the info from the picture recordsdata with the assistance of  Optical persona popularity (OCR). There’s a library Tesseract that makes use of OCR to transform symbol to textual content records.
- pdf to Textual content: Â We have now more than one Python programs to transform the info into textual content. With the PyPDF2 library, pdf records may also be extracted within the .textual content document.
- Information augmentation: if our bought records isn’t very enough for our downside commentary then we will be able to generate faux records from the present records via Synonym substitute, Again Translation, Bigram flipping, or Including some noise in records. This system is referred to as Information augmentation.
2. Textual content Cleansing :
On occasion our bought records isn’t very blank. it is going to include HTML tags, spelling errors, or particular characters. So, letâs see some tactics to wash our textual content records.
- Unicode Normalization: if textual content records would possibly include symbols, emojis, graphic characters, or particular characters. Both we will be able to take away those characters or we will be able to convert this to machine-readable textual content. Â
Python3
|
|
Output :
b'GeeksForGeeks xf0x9fx98x80' b'xe0xa4x97xe0xa5x80xe0xa4x95xe0xa5x8dxe0xa4xb8 xe0xa4xabxe0xa5x89xe0xa4xb0 xe0xa4x97xe0xa5x80xe0xa4x95xe0xa5x8dxe0xa4xb8 ????'
- Regex or Common Expression: Common Expression is the software this is used for looking the string of explicit patterns. Â Assume our records include telephone quantity, email-Identity, and URL. we will be able to to find such textual content the usage of the common expression. After that both we will be able to stay or take away such textual content patterns as consistent with necessities.
- Spelling corrections:Â When our records is extracted from social media. Spelling errors are quite common if that’s the case. To conquer this downside we will be able to create a corpus or dictionary of the most typical mistype phrases and exchange those commonplace errors with the proper phrase.
Python3
|
|
Output:
gfg GFG Geeks Studying in combination url electronic mail
3. Textual content Preprocessing:
NLP tool principally works on the sentence degree and it additionally expects phrases to be separated on the minimal degree.
Our wiped clean textual content records would possibly include a gaggle of sentences. and each and every sentence is a gaggle of phrases. So, first, we want to Tokenize our textual content records.
- Tokenization: Tokenization is the method of segmenting the textual content into a listing of tokens. With regards to sentence tokenization, the token might be sentenced and in relation to phrase tokenization, it is going to be the phrase. This can be a just right concept to first entire sentence tokenization after which phrase tokenization, right here output would be the record of lists. Tokenization is carried out in each and every & each and every NLP pipeline.
- Lowercasing: This step is used to transform all of the textual content to lowercase letters. This comes in handy in more than a few NLP duties corresponding to textual content classification, knowledge retrieval, and sentiment research.
- Forestall phrase elimination: Forestall phrases are often going on phrases in a language corresponding to âtheâ, âandâ, âaâ, and many others. They’re generally got rid of from the textual content all over preprocessing as a result of they don’t elevate a lot that means and will purpose noise within the records. This step is utilized in more than a few NLP duties corresponding to textual content classification, knowledge retrieval, and subject modeling.
- Stemming or lemmatization: Stemming and lemmatization are used to cut back phrases to their base shape, which is able to assist cut back the vocabulary dimension and simplify the textual content. Stemming comes to stripping the suffixes from phrases to get their stem, while lemmatization comes to decreasing phrases to their base shape in response to their a part of speech. This step is often utilized in more than a few NLP duties corresponding to textual content classification, knowledge retrieval, and subject modeling.
- Taking out digit/punctuation: This step is used to take away digits and punctuation from the textual content. This comes in handy in more than a few NLP duties corresponding to textual content classification, sentiment research, and subject modeling.
- POS tagging: POS tagging comes to assigning part of speech tag to each and every phrase in a textual content. This step is often utilized in more than a few NLP duties corresponding to named entity popularity, sentiment research, and mechanical device translation.
- Named Entity Popularity (NER): NER comes to figuring out and classifying named entities in textual content, corresponding to other people, organizations, and places. This step is often utilized in more than a few NLP duties corresponding to knowledge extraction, mechanical device translation, and question-answering.
Python3
|
|
Output:
Authentic textual content: GeeksforGeeks is an excessively well-known edutech corporate within the IT business.
Preprocessed tokens: ['geeksforgeeks', 'famous', 'edutech', 'company', 'industry']
POS tags: [('geeksforgeeks', 'NNS'), ('famous', 'JJ'), ('edutech', 'JJ'),
('company', 'NN'), ('industry', 'NN')]
Named entities: (S geeksforgeeks/NNS well-known/JJ edutech/JJ corporate/NN business/NN)
Right here, Forestall phrase elimination, Stemming and lemmatization, Taking out digit/punctuation, and lowercasing are the most typical steps utilized in lots of the pipelines.
4 . Function Engineering:
In Function Engineering, our primary time table is to constitute the textual content within the numeric vector in this type of method that the ML set of rules can perceive the textual content characteristic. In NLP this technique of function engineering is referred to as Textual content Illustration or Textual content Vectorization.
There are two maximum commonplace approaches for Textual content Illustration.
1. Classical or Conventional Means:
Within the conventional method, we create a vocabulary of distinctive phrases assign a novel identity (integer price) for each and every phrase. after which exchange each and every phrase of a sentence with its distinctive identity. Â Right here each and every phrase of vocabulary is handled as a function. So, when the vocabulary is huge then the function dimension will develop into very massive. So, this makes it difficult for the ML style.
One Sizzling Encoder:Â Â
One Sizzling Encoding represents each and every token as a binary vector. First mapped each and every token to integer values. after which each and every integer price is represented as a binary vector the place all values are 0 excluding the index of the integer. index of the integer is marked via 1.
Python3
|
|
Output:
Tokenized Sentences : ['geeks for geeks', 'geeks learning together',
'geeks for geeks is famous for dsa', 'learning dsa']
vocabulary : {'geeks': 1, 'for': 2, 'finding out': 3, 'in combination': 4, 'is': 5, 'well-known': 6, 'dsa': 7}
OneHotEncoded vector for sentence : " geeks for geeks "is
[[1, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0]]
Bag of Phrase(Bow):Â
 A bag of phrases best describes the prevalence of phrases inside of a report or no longer. It simply assists in keeping observe of phrase counts and ignores the grammatical main points and the phrase order.
Code block
Python3
|
|
Output:
Our Corpus: ['geeksforgeeks', 'geeks learning together',
'geeksforgeeks is famous for dsa', 'learning dsa']
Our vocabulary: {'geeksforgeeks': 4, 'geeks': 3, 'finding out': 6,
'in combination': 7, 'is': 5, 'well-known': 1, 'for': 2, 'dsa': 0}
BoW illustration for geeksforgeeks [[0 0 0 0 1 0 0 0]]
BoW illustration for geeks finding out in combination [[0 0 0 1 0 0 1 1]]
BoW illustration for geeksforgeeks is known for dsa [[1 1 1 0 1 1 0 0]]
Bow illustration for 'finding out dsa from geeksforgeeks': [[1 0 0 0 1 0 1 0]]
Bag of n-grams:
 In Bag of Phrases, there is not any attention of the words or phrase order. Bag of n-gram tries to unravel this downside via breaking textual content into chunks of n steady phrases.
Python3
|
|
Output:
Our Corpus: ['geeksforgeeks', 'geeks learning together',
'geeksforgeeks is famous for dsa', 'learning dsa']
Our vocabulary:
{'geeksforgeeks': 9, 'geeks': 6, 'finding out': 15, 'in combination': 18, 'geeks finding out': 7,
'finding out in combination': 17, 'geeks finding out in combination': 8, 'is': 12, 'well-known': 1, 'for': 4,
'dsa': 0, 'geeksforgeeks is': 10, 'is known': 13, 'well-known for': 2, 'for dsa': 5,
'geeksforgeeks is known': 11, 'is known for': 14, 'well-known for dsa': 3, 'finding out dsa': 16}
Ngram illustration for "geeksforgeeks" is [[0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]]
Ngram illustration for "geeks finding out in combination" is [[0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 1 0 1 1]]
Ngram illustration for "geeksforgeeks is known for dsa" is
[[1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 0]]
Ngram illustration for 'finding out dsa from geeksforgeeks in combination' is
[[1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 1]]
The output displays that the enter textual content has been tokenized into sentences and processed to take away any sessions and convert to lowercase. The vectorizer then computes the Bag of n-grams illustration of each and every sentence, and the vocabulary utilized by the vectorizer is outlined. In any case, the n-gram illustration of a brand new textual content is computed and revealed. The n-gram representations are within the type of a sparse matrix, the place each and every row represents a sentence and each and every column represents an n-gram within the vocabulary. The values within the matrix point out the frequency of the corresponding n-gram within the sentence.
TF-IDF (Time period Frequency â Inverse Report Frequency):
 In all of the above tactics,  Every phrase is handled similarly. TF-IDF tries to quantify the significance of a given phrase relative to the opposite phrase within the corpus.  it’s principally utilized in Data retrieval.
- Time period Frequency (TF): TF measures how steadily a phrase happens within the given report. it’s the ratio of the selection of occurrences of a time period or phrase (t ) in a given report (d) to the full selection of phrases in a given report (d).

- Inverse report frequency (IDF): IDF measures the significance of the phrase around the corpus. it down the load of the phrases, which often happen within the corpus, and up the load of uncommon phrases.

- TF-IDF rating is the made of TF Â and IDF.

Python3
|
|
Output:
Our Corpus: ['geeksforgeeks', 'geeks learning together', 'geeksforgeeks is famous for dsa', 'learning dsa'] vocabulary ['dsa', 'famous', 'for', 'geeks', 'geeksforgeeks', 'is', 'learning', 'together'] IDF for all phrases within the vocabulary : [1.51082562 1.91629073 1.91629073 1.91629073 1.51082562 1.91629073 1.51082562 1.91629073] TFIDF illustration for "geeksforgeeks" is [[0. 0. 0. 0. 1. 0. 0. 0.]] TFIDF illustration for "geeks finding out in combination" is [[0. 0. 0. 0.61761437 0. 0. 0.48693426 0.61761437]] TFIDF illustration for "geeksforgeeks is known for dsa" is [[0.38274272 0.48546061 0.48546061 0. 0.38274272 0.48546061 0. 0. ]] TFIDF illustration for 'finding out dsa from geeksforgeeks' is [[0.57735027 0. 0. 0. 0.57735027 0. 0.57735027 0. ]]
Neural Means (Phrase embedding): Â
The above methodology isn’t excellent for complicated duties like Textual content Era, Textual content summarization, and many others. and they may be able toât perceive the contextual that means of phrases.  However within the neural method or phrase embedding, we attempt to incorporate the contextual that means of the phrases. Right here each and every phrase is represented via actual values because the vector of mounted dimensions.
As an example :
aircraft =[0.7, 0.9, 0.9, 0.01, 0.35] kite =[0.7, 0.9, 0.2, 0.01, 0.2]
Right here each and every price within the vector represents the measurements of a few options or high quality of the phrase which is made up our minds via the style after coaching on textual content records. This isn’t interpretable for people however Only for illustration functions. We will be able to perceive this with the assistance of the under desk.
|
 |
aircraft |
kite |
|---|---|---|
|
Sky |
0.7 |
0.7 |
|
Fly |
0.9 |
0.9 |
|
Shipping |
0.9 |
0.2 |
|
Animal |
0.01 |
0.01 |
|
Devour |
0.35 |
0.2 |
Now, The issue is how are we able to get those phrase embedding vectors.Â
There are following tactics to care for this.
1. Educate our personal embedding layer:
There are two tactics to coach our personal phrase embedding vector :
- CBOW (Steady Bag of Phrases): On this case, we expect the middle phrase from the given set of context phrases i.e earlier and afterwords of the middle phrase. Â
     As an example :
             I’m finding out Herbal Language Processing from GFG.
              I’m finding out Herbal _____?_____ Processing from GFG.
.png)
CBOW
- SkipGram: Â On this case, we expect the context phrase from the middle phrase. Â
     As an example :
             I’m finding out Herbal Language Processing from GFG.
              I’m __?___ _____?_____ Language ___?___ ____?____ GFG.
Â
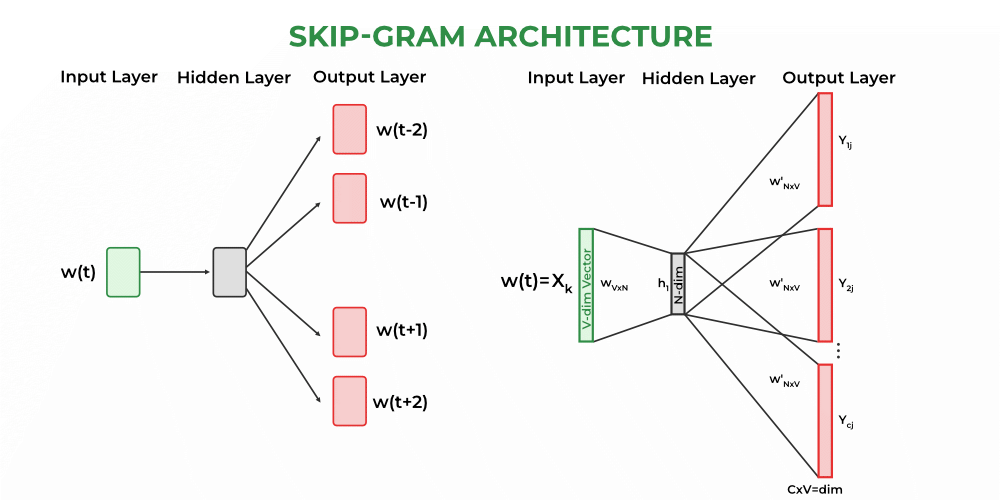
Skip-Gram
2. Pre-Skilled Phrase Embeddings :
Those fashions are educated on an excessively massive corpus. We import from Gensim or Hugging Face and used it in keeping with our functions.
Probably the most hottest pre-trained embeddings are as follows :
Python3
|
|
Output:
Similarity between 'be informed' and 'finding out' the usage of Word2Vec: 0.637 Similarity between 'india' and 'indian' the usage of Word2Vec: 0.697 Similarity between 'popularity' and 'well-known' the usage of Word2Vec: 0.326
Python3
|
|
Output:
Similarity between 'be informed' and 'finding out' the usage of GloVe: 0.768 Similarity between 'india' and 'indian' the usage of GloVe: 0.764 Similarity between 'popularity' and 'well-known' the usage of GloVe: 0.507
Python3
|
|
Output:
Similarity between 'be informed' and 'finding out' the usage of Word2Vec: 0.642 Similarity between 'india' and 'indian' the usage of Word2Vec: 0.708 Similarity between 'popularity' and 'well-known' the usage of Word2Vec: 0.519
5. Type Construction:
Heuristic-Primarily based Type
In the beginning of any challenge. When we don’t have any very fewer records, then we will be able to use a heuristic method. The heuristic-based method could also be used for the data-gathering duties for ML/DL style. Common expressions are in large part utilized in this kind of style.
- Lexicon-Primarily based-Sentiment- Research: Works via counting Certain and Destructive phrases in sentences.
- Wordnet: It has a database of phrases with synonyms, hyponyms, and meronyms. It makes use of this database for fixing rule-based NLP duties.
Gadget Studying Type:
- Naive Bayes: It’s used for the classification activity. This can be a workforce of classification algorithms in response to Bayesâ Theorem. It assumes that each and every function has an equivalent and unbiased contribution to the results. Naive Bayes is steadily used for report classification duties, corresponding to sentiment research or junk mail filtering.
- Reinforce Vector Gadget: This could also be used for classification duties. This can be a common supervised finding out set of rules used for classification and regression research. It makes an attempt to seek out the most efficient hyperplane that separates the info issues into other categories whilst maximizing the margin between the hyperplane and the nearest records issues. Within the context of NLP, SVM is steadily used for textual content classification duties, corresponding to sentiment research or subject classification.
- Hidden Markov Type: HMM is a statistical style used to constitute a series of observations which are generated via a series of hidden states. Within the context of NLP, HMM is steadily used for speech popularity, part-of-speech tagging, and named entity popularity. HMM assumes that the state transitions are dependent best at the present state and the remark depends best at the present state.
- Conditional Random Fields: CRF is a kind of probabilistic graphical style used for modeling sequential records the place the output is a series of labels. It’s very similar to HMM, however in contrast to HMM, CRF can keep in mind extra complicated dependencies between the output labels. Within the context of NLP, CRF is steadily used for named entity popularity, part-of-speech tagging, and data extraction. CRF can care for extra complicated enter options, making it extra robust than HMM.
Deep Studying Type :
Recurrent neural networks
Recurrent neural networks are a selected magnificence of man-made neural networks which are created with the purpose of processing sequential or time sequence records. It’s essentially used for herbal language processing actions together with language translation, speech popularity, sentiment research, herbal language manufacturing, abstract writing, and many others. In contrast to feedforward neural networks, RNNs come with a loop or cycle constructed into their structure that acts as a âreminiscenceâ to carry onto knowledge over the years. This distinguishes them from feedforward neural networks. This permits the RNN to procedure records from assets like herbal languages, the place context is a very powerful.
The elemental thought of RNNs is they analyze enter sequences one part at a time whilst keeping up observe in a hidden state that comprises a abstract of the collectionâs earlier parts. The hidden state is up to date at each and every time step in response to the present enter and the former hidden state. Â This permits RNNs to seize the temporal dependencies between parts of the collection and use that knowledge to make predictions.

Recurrent neural networks
Operating: The basic part of an RNN is the recurrent neuron, which receives as inputs the present enter vector and the former hidden state and generates a brand new hidden state as output. And this output hidden state is then used because the enter for the following recurrent neuron within the collection. An RNN may also be expressed mathematically as a series of equations that replace the hidden state at each and every time step:
St= f(USt-1+Wxt+b)
The place,
- St = Present state at time t
- xt = Enter vector at time t
- St-1 = Earlier state at time t-1
- U = Weight matrix of recurrent neuron for the former state
- W = Weight matrix of enter neuron
- b = Bias added to the enter vector and former hidden state
- f = Activation purposes
And the output of the RNN at each and every time step might be:
yt = g(VSt+c)
The place,
- yt = Output at time t
- V = Weight matrix for the present state within the output layer
- C = Bias for the output transformations.
- g = activation serve as
Right here, W, U, V, b, and c are the learnable parameters and it’s optimized all over the backpropagation.
Fashions must procedure numerous tokens. When it’s processing a far off token from the primary token, The importance of the primary token begins reducing, So, it fails to narrate with beginning token to the far-off token. This may also be have shyed away from with specific state control via the usage of gates.
There are two architectures that attempt to clear up this downside.
- Lengthy non permanent reminiscence (LSTM)Â
- Gated relay unit (GRU)
Lengthy Quick-Time period Reminiscence (LSTM):
 Lengthy Quick-Time period Reminiscence Networks are a complicated type of RNN style, and it handles the vanishing gradient downside of RNN. It best recollects the a part of the context which has a significant function in predicting the output price. LSTMs serve as via selectively passing or keeping knowledge from one-time step to the following the usage of the mix of reminiscence cells and gating mechanisms.Â
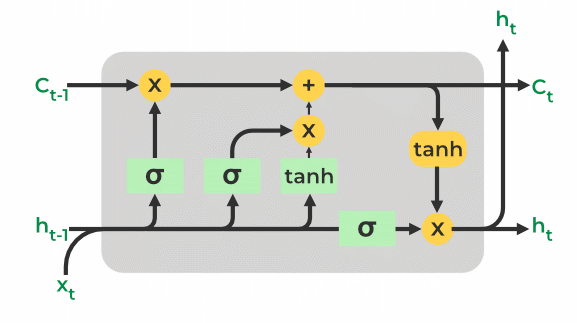
Lengthy Quick-Time period Reminiscence (LSTM)
The LSTM mobile is made up of plenty of portions, corresponding to:
- Mobile state (C): The LSTMâs reminiscence part is the place the ideas from the previous section is saved at the moment. Â Gates that control the float of information into and out of the LSTM mobile are used to move it via.
- Hidden state (h): That is the LSTM mobileâs output, which is a changed illustration of the mobile state. Â It can be implemented to predictions or transferred to a next LSTM mobile within the collection.
- Overlook gate (f): The omit gate gets rid of the info this is now not related within the mobile state. The gate receives two inputs, xt (enter on the present time) and ht-1 (earlier hidden state), that are multiplied with weight matrices, and bias is added. The result’s handed by the use of an activation serve as, which provides a binary output i.e. True or False.
- Enter Gate(i): The enter gate determines what portions of the enter must be added to the mobile state via making use of a sigmoid activation serve as to the present enter and the former hid state as inputs. The brand new values which are added to the mobile state are created via multiplying the output of the enter gate (once more, a fragment between 0 and 1) via the output of the tanh block. The present mobile state is created via including this gated vector to the former mobile state.
- Output Gate(o): The output gate takes the a very powerful records and outputs it from the state of the present mobile. Â First, a vector is created within the mobile the usage of the tanh serve as. The information is then filtered via the values to be remembered the usage of the inputs ht-1 and xt, and the ideas is then managed the usage of the sigmoid serve as. The vectorâs values and the managed values are in spite of everything multiplied and provided as enter and output to the next mobile, respectively.
The 2-state vector for LSTM represents the present state.Â
GRU (Gated Recurrent Unit):Â
 Gated Recurrent Unit (GRU) could also be the complicated type of RNN. which solves the vanishing gradient downside. Like LSTMs, GRUs even have gating mechanisms that permit them to selectively replace or omit knowledge from the former time steps. Then again, GRUs have fewer parameters than LSTMs, which makes them sooner to coach and no more susceptible to overfitting. The 2 gates in GRUs are the reset gate and the replace gate, which keep an eye on the float of data within the community. Â

GRU (Gated Recurrent Unit):
- Replace Gate: this controls the quantity of data handed via the following state.Â
- Relaxation Gate: It comes to a decision whether or not the former mobile state is necessary or no longer.
6. Analysis :
Analysis matric relies on the kind of NLP activity or downside. Right here I’m list one of the vital common strategies for analysis in keeping with the NLP duties.
- Classification: Accuracy, Precision, Recall, F1-score, AUC
- Collection Labelling: Fl-Ranking
- Data Retrieval : Imply Reciprocal rank(MRR), Imply Moderate Precision (MAP),
- Textual content summarization: ROUGE
- Regression [Stock Market Price predictions, Temperature Predictions]: Root Imply Sq. Error, Imply Absolute Proportion Error
- Textual content Era: BLEU (Bi-lingual Analysis Figuring out), Perplexity
- Gadget Translation: BLEU (Bi-lingual Analysis Figuring out), METEOR
7. Deployment
Creating a educated NLP style usable in a manufacturing atmosphere is referred to as deployment. The right deployment procedure can range in response to the platform and use case, then again, the next are some standard processes that can be concerned:
- Export the educated style: The educated style will have to first be exported from the educational setting in an effort to be loaded and utilized in a manufacturing setting. This may occasionally entail holding the styleâs structure, parameters, and any further pertinent artifacts, like vocabulary or embeddings.
- Get ready the enter pipeline: It’s required to arrange the enter pipeline such that the enter records is preprocessed in the similar means because it used to be all over coaching prior to the style can be utilized to provide predictions. Relying at the explicit NLP activity, this will likely require tokenization, normalization, or different preparatory procedures.
- Arrange the inference provider: Putting in place an inference provider that may give predictions the usage of the educated style comes subsequent after the enter pipeline has been put in. To perform this, it can be essential to increase a internet server or different API endpoint that may settle for requests containing enter records, preprocess it the usage of the enter pipeline, after which give it to the style for prediction.
- Track efficiency and scale: Following deployment, it is necessary to regulate the styleâs efficiency and regulate scaling as essential to control permutations in site visitors and insist. Putting in place efficiency metrics to watch the styleâs effectiveness and enhancing the infrastructure as essential to make sure optimum efficiency is also required.
- Steady growth: In any case, itâs necessary to regulate and expand the deployed style over the years. This would entail getting person comments, retraining the style with recent records, or adjusting the styleâs parameters or structure to spice up efficiency.