
Data may also be moderately of a double-edged sword for modern day industry. On one hand, it is important to the decision-making process. In most cases talking, the standard of alternatives complements as the volume of related knowledge evaluated boosts. Put merely, the additional info there may be, the extra angles there are for a priority to be looked at, which in the end implies extra revel in that may be consisted of right into a decision-making process, main to bigger high quality alternatives.
Even past decision-making, knowledge is an important to the efficiency of modern day industry. Retail industry require to stay consumer touch main points reminiscent of addresses, and fee card knowledge on document with the intention to save you making the customer re-enter this main points every time they keep in touch with the industry. Banking industry require as a way to tell their shoppers the place their money is at any period of time. Video gaming industry require to stay online game state. Personnels require basic information about all group of workers individuals so as to be able to paintings correctly. Those datasets are elementary to the elemental operations of those industry.
However, knowledge can cause large complications for industry. Data breaches could cause sheer drops in self-confidence in a selected industry and massive financial losses. Data espionage via competitors can significantly problem a industry’s aggressive practicality. Vital knowledge can get misplaced or broken. Deficient knowledge governance could cause unsuitable, unreliable, or out-of-date knowledge current to folks with out suitable notification. Indisputably, it could possibly cause the precise opposite of what used to be mentioned above– moderately of data inflicting enhanced selection making, it could possibly reason significantly poorer selection making.

( Arcady/Shutterstock)
There are actually couple of different parts that may have a related more or less large swing outcome typically industry luck.
Data Risks Purpose Centralized Knowledge Control
Supplied the massive magnitude of this swing– suitable knowledge control can cause so much very good then again whilst dangerous knowledge control can cause so much bad– the best follow for years used to be to stay primary keep watch over over all industry knowledge. The anticipation used to be {that a} central organization of highly-paid knowledge control consultants are most productive in assembling knowledge governance tips, executing, implementing, and complying with the ones tips, together with averting the hazards equipped via the double-edged sword from inflicting over the top injury.
The elemental thesis of central knowledge control is that there’s a primary repository of industrial knowledge that may simply be accessed by the use of protected and well-governed necessities that lend a hand limit potential direct exposures to breaches and espionage. Having all the knowledge in a single location significantly streamlines the enforcement of safety and private privateness tips and makes it conceivable for monitoring, keep watch over, and reporting of data use. Additionally, procedures are installed location to make certain that all knowledge positioned into this repository is prime quality– suggesting it’s suitable, overall, present, well-documented, and well-integrated with different industry data-sets. It’s usually conceivable to make other warranties related to knowledge balance and different knowledge acquire get entry to to provider ranges. Having in truth all knowledge saved in the exact same repository likewise makes knowledge cataloging and enterprise-wide seek so much more uncomplicated to hold out.
Indisputably, the central knowledge control method does an inexpensive process of blunting the dangerous facet of the guidelines sword. The problem is that it likewise blunts the other of the sword, proscribing the overall potency of data utilization inside of a industry.
As an example, a brand-new dataset may happen this is drastically essential to creating a selected selection. When knowledge isn’t centrally treated that dataset may also be integrated temporarily into the decision-making process. However, when knowledge is centrally treated, a hold-up is continued because the central organization positive aspects get entry to to the brand-new dataset and brings it into the central repository whilst keeping up all of the high quality and data mixture necessities. It’s not unusual for this process to take a lot of months. By the point the guidelines is finally presented from the primary repository, its price may have these days decreased because of this time hold-up. Therefore, in a large number of circumstances, central knowledge control can lower organizational dexterity.

( maglyvi/Shutterstock)
Moreover, having a human organization in command of ingress into the central knowledge repository necessarily restricts the scalability of an organization. The volume of datasets presented to an organization is instantly expanding. Doing suitable cleaning, mixture and high quality control on every dataset is a time eating process and wishes a minimal of a few area wisdom within the area of the dataset. Handing off legal responsibility for this processing to a unmarried human organization produces an enormous visitors jam in organizational knowledge pipelines. This human organization restricts the aptitude of the corporate to develop into brand-new domain names, or even to develop inside of current domain names.
Let the Issues We Required Now Are living Outdoor
As a result of so much time and effort calls for to be invested to get knowledge into a unconditionally ruled and included layout inside of the primary repository, there exists a large temptation to stop the process totally. As an example, it’s conceivable to chop corners via discarding datasets into knowledge lakes with out to start with going via a high quality assurance process. Moreover, knowledge can take a seat inside of knowledge silos past (or even inside of) any form of primary repository. Such strategies lend a hand to triumph over the dexterity and scalability hindrances of centralized keep watch over, then again provide different hindrances. Data silos are usually produced by the use of an ad-hoc process: a personal or organization takes some supply knowledge, boosts it in several strategies, and discards the result in a silo repository or knowledge lake on their very own and/or others to make use of. Those knowledge silos usually have substantial price within the non permanent, then again temporarily decline as time is going on. Occasionally, knowledge silos no longer simply decline in time, then again actually finally end up being hazardous to realize get entry to to because of out-of-date or faulty knowledge bobbing up from absence of maintenance, and failure to stick up-to-the-minute with knowledge non-public privateness and sovereignty necessities. Normally, they by no means ever applied licensed knowledge governance practices in the first actual location and provide safety vulnerabilities for the industry.
Additionally, the value of a data silo is normally limited to the builders of the dataset, whilst the rest of the corporate remains uninformed of its presence until they’re obviously alerted and instantly tutored in its syntax and semantics. Silos simply finally end up being tougher to find in time as institutional reminiscence compromises with group of workers member turnover and movement all over methods. Because of absence of maintenance, they likewise finally end up being tougher to include with different industry knowledge in time. A lot effort is squandered within the initial manufacturing of those knowledge silos, but their impact is specific in each breadth and time. Occasionally, the opposite holds true: knowledge silos have over the top impact, the place different methods assemble dependences on most sensible of those silos which are launched with unapproved knowledge governance necessities, and all of the hazardous side-effects of poorly ruled knowledge spreads all over the industry.
Returning to the “double-sword” instance: whilst the central knowledge control method dulls each ends of the sword, the guidelines silo method hones the unsuitable facet of the sword: it preserves nearly all of the hazards intrinsic in knowledge control, whilst supplying (at best) simply limited non permanent benefits with reference to improving organizational decision-making.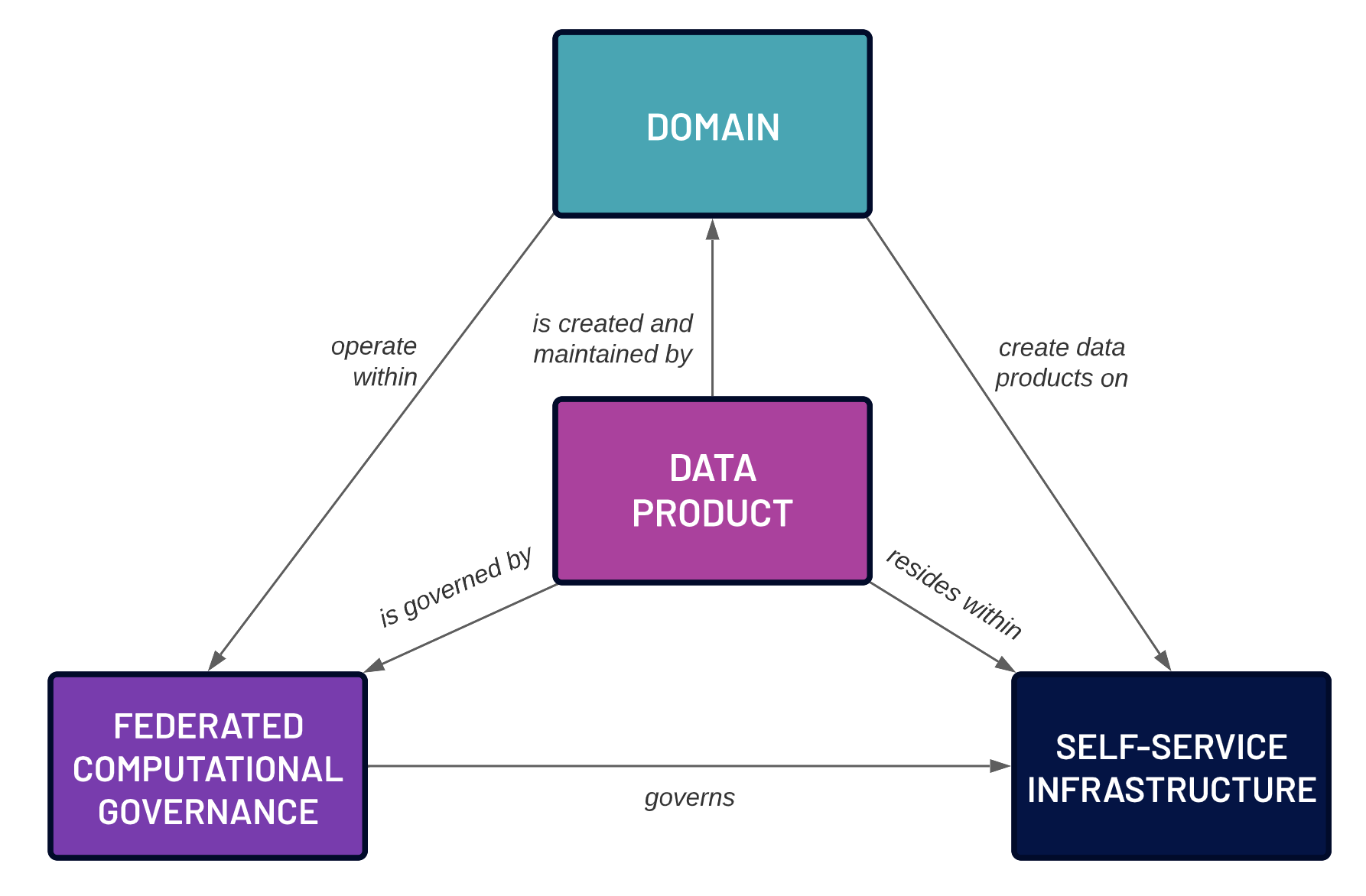
A New Methodology
Ultimately, what we want is all of the advantages of central knowledge control, with out the downsides round dexterity and scalability. Merely put, we need to scale all of the actions of the central organization, and no matter that they do round knowledge governance and mixture, in a decentralized taste via dispersing their actions to area house owners with out compromising the governance and data high quality you get with a central organization. An interesting option to fulfill this function is the “Knowledge Merchandise” method: a idea that has in truth only recently been obtaining traction, particularly inside the context of data markets, the “Knowledge Mesh”, and different rising organizational knowledge control best practices.
Knowledge Merchandise, as one way, want an excessive shift in mindset all over the process of creating knowledge presented inside of an organization. Previously, making knowledge presented to different methods used to be a low-effort process, together with one among 2 conceivable strategies. The first actual method is to simply hand a dataset over in its totality to the opposite methods. The dataset then finally ends up being a silo within the possession of the ones different methods, inflicting duplicated effort as every device may perform related knowledge cleaning and mixture procedures. Therefore the non permanent good thing about low-effort sharing ends up in long-lasting problems with reference to squandered bodily and personnels bobbing up from knowledge duplication and related procedures. [These disadvantages are on top of the other disadvantages of data silos discussed above.] The 2d method contains handing off the dataset to the central organization, which is then strained with the paintings of doing all of the upfront effort in making the dataset useful in order that different methods can make the most of the dataset with much less duplicated effort. In both case, the crowd that owns the dataset– which perhaps comprehends it the very best– takes little or no legal responsibility within the effort related to making it usually useful to different methods. This effort is moderately placed on different teams inside the corporate.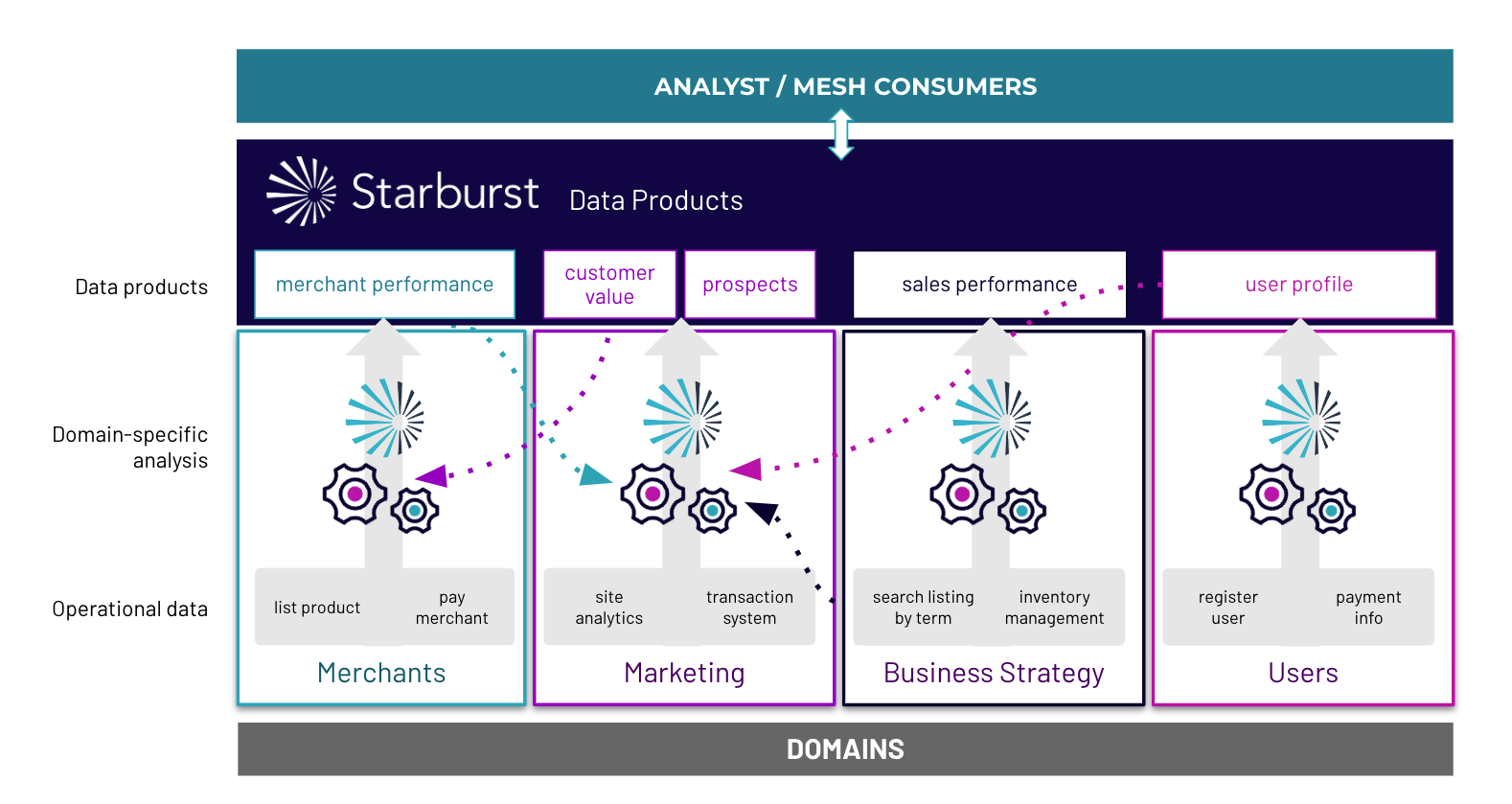
The intense shift in mindset at the back of the Knowledge Merchandise method is to transport a lot of this effort to the crowd that owns the dataset. Data cleansing up and mixture, along with cataloging and forms, is therefore performed via the crowd that comprehends the guidelines perfect. A lot of the guidelines governance tasks, that have been previously performed via a central organization, now fall below the duty of the dataset house owners. Those house owners are therefore charged with a long run willpower to creating the dataset presented, and preserving its long run knowledge high quality and repair price. Whilst there may be some non permanent discomfort, because the process of sharing a dataset finally ends up being way more integrated, the long run benefits significantly exceed this non permanent discomfort.
The bodily garage of an Data Merchandise, in conjunction with the equipment had to question this knowledge, isn’t all the time the duty of the Data Merchandise proprietor. It’s nonetheless conceivable to wish that Data Merchandise house owners employ central knowledge garage and inquiry layers, that make the most of standardized safety and private privateness procedures, when making the guidelines presented all over an organization. However, the very important difference from the traditional central method is that no approval process from a central organization is needed for ingress of an Data Merchandise into the repository. So long as the Data Merchandise proprietor takes legal responsibility for the long run maintenance and forms of the dataset, and will ascertain that they’re keeping up the set of data governance tips outlined via the corporate, the dataset finally ends up being in an instant presented with out the months-long hold-up below earlier strategies.
To be efficient, Data Merchandise house owners should imagine past the moment set of teams inside the corporate that at this time want get entry to to the dataset, then again should imagine extra usually: who’re the splendid “shoppers” of this Data Merchandise? What do they require to be efficient? What are their expectancies in regards to the contents of the object? How are we able to have interaction usually the contents and semantics of the dataset so it may be accessed and used by a generic “consumer”?
The requirement for a central organization does no longer vanish when using the Knowledge Merchandise method. The centralized organization nonetheless calls for to specify the guidelines governance necessities and lend a hand with reputation of those necessities when brand-new pieces get introduced. Additionally, they want to figure out with device software providers to offer knowledge garage and inquiry equipment that Knowledge Merchandise house owners can make the most of all over the process of manufacturing and liberating their merchandise. They likewise require to offer coaching in order that Knowledge Merchandise house owners can uncover the right way to make the most of those equipment and determine the data required to hold out very important jobs reminiscent of knowledge mixture with current datasets. It’s usually at hand to offer design template procedures that can be used via a brand-new organization that wants to increase Knowledge Merchandise at quite a lot of ranges of data governance barriers relying upon the intended utilization of the Knowledge Merchandise. In most cases, they likewise stay a world database of identifiers associated with shoppers, suppliers, portions, orders, and so forth that Knowledge Merchandise want to make the most of when describing shared conceptual entities. 
It is very important to take into account that none of those central actions are carried out on a per-dataset foundation. That is an important because of the truth that any job carried out on a per-dataset foundation would visitors jam the intro of brand-new Knowledge Merchandise into the surroundings.
However, the Knowledge Merchandise method is extra detailed to the guidelines silo facet of the tradeoff than the centralized keep watch over facet. Any group– so long as they take long run legal responsibility for the dataset– can increase an Data Merchandise and make it presented in an instant. Just like standard real-world pieces, some pieces will finally end up being efficient and widely-used, while others will finally end up in obscurity or cross “out of provider”. However, in contrast to the guidelines silo method, going “out of provider” is a selected selection via the crowd in command of the Knowledge Merchandise to prevent supporting the continual maintenance tasks of the object and getting rid of its agenda.
As well as, merely as standard real-world pieces featured an expectation of forms on the right way to make the most of the object, a bunch to name when there are issues, and an expectation that the object will increase as consumer necessities regulate, so do Knowledge Merchandise. Likewise, merely as standard pieces require to take advantage of markets reminiscent of Amazon to transmit the agenda in their merchandise to potential shoppers, corporations require to increase markets for Knowledge Merchandise (which may encompass an approval process) in order that Knowledge Merchandise producers and consumers can uncover every different. Moreover, merely as real-world merchandise dealers want to provide the needful metadata about their merchandise in order that it could possibly seem in the right kind places when regarded for, in conjunction with different specs that designate the specs of the object, Knowledge Merchandise house owners require to offer this main points when liberating to a marketplace.
Whilst there are a lot of very important parts for firms to take into accounts when executing the Knowledge Merchandise method, in the end there may be capability for a lot of advantages—- upper dexterity, diminished visitors jams, sooner insights and teams which are empowered to do extra. In as of late’s data-driven global, the aptitude to inspect the perfect knowledge, abruptly, is a vital, and necessarily required function for industry to have. Organizations will uncover luck via accepting a decentralized option to knowledge control via permitting knowledge pushed insights to be temporarily curated and shared all over the industry via Knowledge Merchandise.
In regards to the writer: Daniel Abadi is a Darnell-Kanal instructor of laptop generation on the College of Maryland, Faculty Park and number one researcher at Starburst
Related Merchandise:
Take Complete Merit Of the Value of Data with Data Have compatibility In combination
Data Have compatibility In combination Vs. Knowledge Subject matter: Comprehending the Distinctions
Starburst Publicizes New Knowledge Merchandise Efficiency